In spite of all the hype about deep learning, in my experience over 95% of the time we must deal with plain and simple csv files – in other words, tabular data. So the question for me is, Can we use deep learning for tabular data?
In order to answer this question, I used the Sandander Customer Satisfaction Dataset from Kaggle.I chose this set because it’s much like the datasets our customers usually work with. And it appears that Sandander is trying to do a churn prediction, which is always a hot topic.
Why consider deep learning anyway?
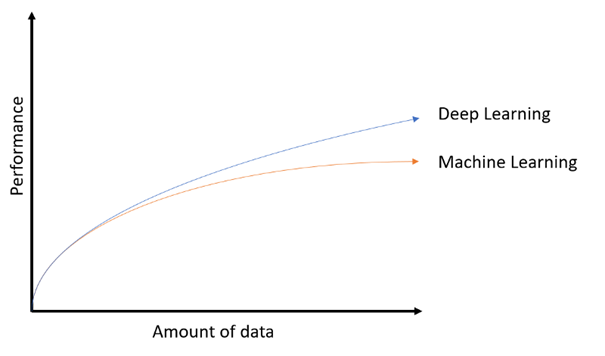
There is this famous graph, presented below, which shows that the more data you throw at the deep learning, the more it improves, whereas traditional ML models hit a plateau.
Data
Our test data has 370 features and around 76,000 data points. We tried to predict whether we would have a happy customer or an unhappy customer. If you look at the data, you will see that around 4% of the customers are unhappy. I did not do any data pre-processing other than feature scaling (meaning that all values fall into the same range). Omitting these extra steps made it easier for most of the algorithms to make predictions.
Test Setup
The test setup is quite straightforward. We used the training data file, scaled their features, and ran the file through some selected algorithms. As an objective function we used the official Kaggle challenge metric which is the area under the ROC curve (receiver operating characteristic). In order to test the setup properly, we used the mean of the cross validation results.
Results
| Algo | auc_score |
|---|---|
| tree | 0.573 |
| extra_tree | 0.644 |
| forest | 0.685 |
| ada_boost | 0.826 |
| bagging | 0.701 |
| grad_boost | 0.835 |
| ridge | 0.791 |
| passive | 0.701 |
| sgd | 0.646 |
| gaussian | 0.523 |
| xgboost | 0.838 |
| deeplearning | 0.770 |
Summary
The above table shows quite clearly that ensemble techniques still perform much better than deep learning out of the box. Another good reason not to choose deep learning is that it’s computationally intensive. Despite these shortcomings, we still have a few good reasons to choose deep learning over traditional methods:
- Combine different types of data: You can combine pictures, free text, and tabular data within one deep learning model, something that can be quite difficult for other ML algorithms.
- Big data: Your tabular data may eventually become big data. When that happens, your deep learning model will keep on improving while the traditional models will have hit a plateau.
- Less feature engineering needed: Traditional ML algorithms usually require a lot of domain-specific knowledge. With deep learning, it’s possible to get great results without requiring much in the way of feature engineering